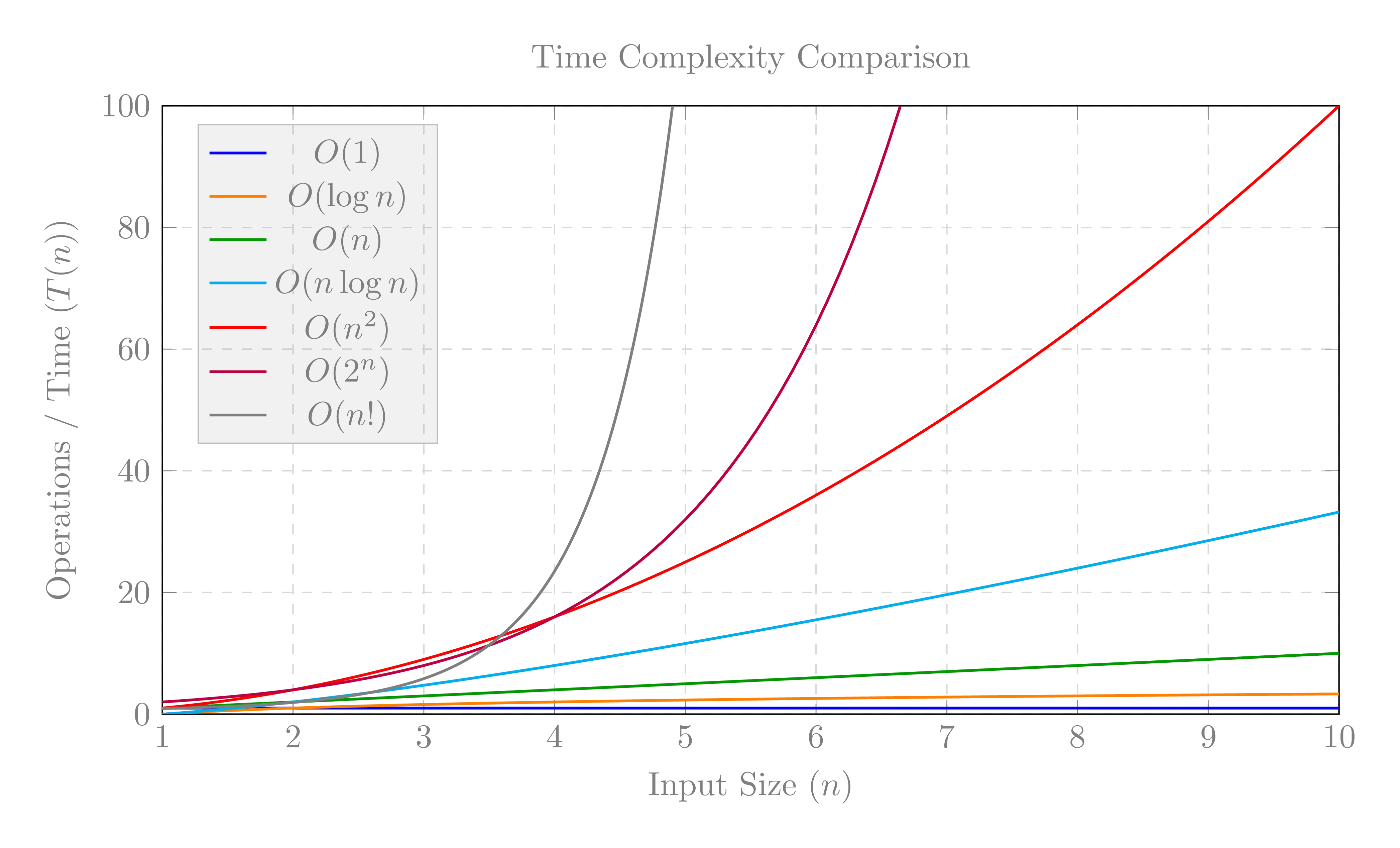
What is the Best Way to Compare Algorithms' Efficiency?
Given two algorithms that perform the same task, what is the best way
to compare their performance? At first glance, one might consider
measuring the runtime of the two algorithms. However, this is not a
reliable metric, as runtime depends heavily on the hardware and can be
highly inconsistent due to real-world conditions, even on the same
machine. To address this problem, scientists have developed a more
theoretical approach called the time complexity of an algorithm. This
measure evaluates how an algorithm's performance scales as the size of
the input increases.
If $n$ is the number of input, then for a given algorithm, there
exists a function $f(n)$ that measures the worst-case runtime of the
algorithm as $n$ varies. The runtime of an algorithm generally follows
a specific trend, such as constant, logarithmic, or linear. However,
as noted, the runtime is significantly influenced by hardware and
physical conditions. Therefore, these functions are often expressed
with additional constant factors, such as:
$f(n) = C_1n + C_0,$
where $C_1$ and $C_0$ are factors that depends on outside conditions.
This expression is quite inconvenient, as we don't usually know what
these constant factors are, so the general rule of thumb to express
the worst-case runtime of an algorithm is through the big-O notation.
For example, if $f(n) = C_1n + C_0$, then it can be said that
$f(n) \in O(n).$
There are many categories of such functions $f(n)$, and the most
important functions used in algorithmic analysis are the constant
function, $f(n)=c$, the logarithm function $f(n) = \log_b(n)$, the
linear function $f(n) = n$, $f(n) = n\log(n)$, the quadratic function
$f(n) = n^2$, other polynomial functions $f(n) = n^d$, the exponential
functions $f(n) = a^n$, and the factorial function $f(n) = n!$.
The Big O, Big Omega, Big Theta, and Their Properties
Merge sort splits the input array into halves, recursively sorts both
halves, then merges two sorted arrays in linear time. Let $T(n)$ be
the time to sort $n$ items. The recurrence is
$T(n) = 2\,T\!\left(\tfrac{n}{2}\right) +
\Theta(n).$
Here $a=2$, $b=2$, and $f(n)=\Theta(n)$ matches Case 2 of the Master
Theorem with $k=0,\;\log_b a=1$, yielding $T(n) \in \Theta(n\,\log
n)$. The merge step uses linear extra space, so space complexity is
$\Theta(n)$.
The Big O Notation
Let
$f$ and
$g$ be real-valued and not necessarily continuous
functions. We say that
$f$ is the big O of
$g$, written
$f(n) = O(g(n)),\quad n \to \infty,$
if there exists some value
$n_0$ such that
$|f(n)| \le M|g(n)|,\quad \forall n \ge n_0.$
for some constant
$M > 0$.
For example, $f(n) = 3n \in O(n)$ because $|3n| \le M|n|$ for $n \ge
0$, and $M$ can be any number greater than or equal to 3. Similarly,
$8n + 5 \in O(n)$ because choosing $M = 9$ and $n_0 = 5$ gives $8n +
5 \le 9n$ for all $n \ge 5$.
Binary search on a sorted array halves the search interval each
iteration. The recurrence is
$T(n) = T\!\left(\tfrac{n}{2}\right) +
\Theta(1).$
With $a=1$, $b=2$, $f(n)=\Theta(1)$, we have $\log_b a = 0$ and Case 2
gives $T(n) \in \Theta(\log n)$. Iterative binary search uses
$\Theta(1)$ extra space; the naive recursive form uses $\Theta(\log
n)$ stack space.
The Big Omega Notation
Big Omega provides a lower bound on the growth of a function. We say
that
$f$ is the big Omega of
$g$, written
$f(n) = \Omega(g(n)),\quad n \to \infty,$
if there exists some value
$n_0$ such that
$|f(n)| \ge M|g(n)|,\quad \forall n \ge n_0,$
for some constant
$M > 0$.
For example, $5n \in \Omega(n)$ since $|5n| \ge M|n|$ with $M = 5$
for all $n \ge 0$. Likewise, $2n^2 + 7n \in \Omega(n^2)$ because for
large enough $n$, the quadratic term dominates.
Using Kahn's algorithm (indegree + queue) or DFS, each vertex is
enqueued/visited a constant number of times and each edge is examined
once. For a DAG with $V$ vertices and $E$ edges, the runtime is
$\Theta(V+E)$; space is $\Theta(V)$ for the queue/stack and
$\Theta(V+E)$ for adjacency lists.
The Big Theta Notation
Big Theta describes a tight bound on the growth of a function. We
say that
$f$ is the big Theta of
$g$, written
$f(n) = \Theta(g(n)),\quad n \to \infty,$
if there exist constants
$M_1, M_2 > 0$ and a value
$n_0$ such that
$M_1|g(n)| \le |f(n)| \le M_2|g(n)|,\quad \forall n \ge n_0.$
For example, $7n + 4 \in \Theta(n)$ because the linear term
dominates and both an upper bound and a lower bound proportional to
$n$ can be found. Similarly, $3n^3 - 2n \in \Theta(n^3)$ because the
cubic term determines the growth rate.
With adjacency lists and a binary heap priority queue:
-
Extract-min occurs $V$ times at $\Theta(\log V)$ each.
-
Decrease-key (relaxation) occurs up to $E$ times at $\Theta(\log V)$
each.
-
Scanning adjacency lists costs $\Theta(E)$ overall.
Total time $\Theta\big((V+E)\log V\big)$; with an array as the queue
it is $\Theta(V^2+E)$; with a Fibonacci heap it becomes
$\Theta(E+V\log V)$.
Useful Properties
- Ignore constants: $c\,f(n) \in \Theta(f(n))$ for any constant
$c>0$.
- Base of logs: $\log_a n \in \Theta(\log_b n)$ for any fixed bases
$a,b>1$.
- Sum dominated by max: $f(n)+g(n) \in \Theta(\max\{f(n),g(n)\})$
if one eventually dominates.
- Products: If $f\in O(g)$ and $h\in O(k)$, then $fh \in O(gk)$.
- Polynomial vs. exponential: For any constant $d>0$ and any $a>1$,
$n^d \in o(a^n)$.
- Transitivity: If $f\in O(g)$ and $g\in O(h)$ then $f\in O(h)$
(similarly for $\Omega$).
The Master Theorem
Many divide-and-conquer algorithms lead to recurrences of the form
$T(n) = a\,T\!\left(\frac{n}{b}\right) + f(n),
\quad a \ge 1,\; b>1,$
where $a$ subproblems of size $n/b$ are solved and $f(n)$ accounts
for splitting/merging work. The Master Theorem gives asymptotic
solutions:
- Case 1: If $f(n) \in O\big(n^{\log_b a - \varepsilon}\big)$
for some $\varepsilon>0$, then $T(n) \in \Theta\big(n^{\log_b a}\big)$.
- Case 2: If $f(n) = \Theta\big(n^{\log_b a}\,\log^k
n\big)$ for some $k \ge 0$, then $T(n) \in \Theta\big(n^{\log_b
a}\,\log^{k+1} n\big)$.
- Case 3: If $f(n) \in \Omega\big(n^{\log_b a + \varepsilon}\big)$
for some $\varepsilon>0$ and $a\,f(n/b) \le c\,f(n)$ for some constant
$c<1$ and all sufficiently large $n$, then $T(n) \in \Theta\big(f(n)\big)$.
Runtime Analysis of an Algorithm
Example 1: Merge Sort
Merge sort splits the input array into halves, recursively sorts
both halves, then merges two sorted arrays in linear time. Let
$T(n)$ be the time to sort $n$ items. The recurrence is
$T(n) = 2\,T\!\left(\tfrac{n}{2}\right) +
\Theta(n),$
which solves to $T(n) \in \Theta(n\,\log n)$ by the Master Theorem.
The merge step uses linear extra space, so space complexity is
$\Theta(n)$.
Example 2: Binary Search
Binary search on a sorted array halves the search interval each
iteration. The recurrence is
$T(n) = T\!\left(\tfrac{n}{2}\right) +
\Theta(1) \;\Rightarrow\; T(n) \in \Theta(\log n).$
Iterative binary search uses $\Theta(1)$ extra space; the naive
recursive form uses $\Theta(\log n)$ stack space.
Example 3: Topological Sort
Kahn's algorithm or a DFS-based algorithm visits each vertex and
edge a constant number of times. For a directed acyclic graph (DAG)
with $V$ vertices and $E$ edges, the runtime is $\Theta(V+E)$.
Example 4: Dijkstra's Algorithm
With a binary heap (priority queue) and adjacency lists, Dijkstra
runs in $\Theta\big((V+E)\log V\big)$. Using an array as the queue
yields $\Theta(V^2+E)$; with a Fibonacci heap it becomes
$\Theta(E+V\log V)$.
The Fundamental Functions of Algorithmic Analysis
The constant function
The constant time complexity function, denoted
$f(n) = c \in O(1),$
does not depend on the size of the input (unless the size of the
input is exceptionally large). Some examples of algorithms with this
complexity are:
-
Accessing array index: Accessing elements at a specific index in
an array takes constant time because an array begins at a fixed
memory location. The memory location of each element can be
directly calculated using the element's size and its index, which
is a constant operation.
-
Basic arithmetic and bitwise operations: Computers usually uses
8-bit, 16-bit, 32-bit, and 64-bit for integers and floating
point numbers. Addition, subtraction, multiplication, or
division of two numbers are considered constant time complexity
because they are limited to a certain amount of bit. However,
for large number arithmetic with arbitrary precision, the time
complexity will no longer be constant.
Bitwise operations like AND, OR, and XOR also take constant time
because, again, primitive data types are limited to a certain
size on the computer.
-
Variable assignment: For primitive data types such as integers,
floating points, characters, and boolean, the assignment operator
takes constant time complexity because the size of these variables
are pre-determined. However, for non-primitive data types such as
strings, the assignment operator takes linear time, $O(n)$ because
strings are arrays of characters.
-
Returning a value from a function: Returning a pre-defined value
also takes constant time.
-
Inserting a node, or jump to the next/previous node in a linked
list: These operation are constant because each node holds the
address of the next node (for a singly linked list), or the
address of both the previous and the next node (for a doubly
linked list).
-
Pushing and popping on stack. Insertion and removal from queue.
-
Hashmap operations: Insert, access, and search operations in a
hash map take constant time on average (ideally). These operations
are $O(1)$ on average because a hash map uses a bucket array, and
accessing elements in an array is $O(1)$. The hash function
computes an index for a given key, and ideally, keys are
distributed evenly across the buckets. However, if all keys end up
in the same bucket due to hash collisions (e.g., in separate
chaining), these operations degrade to $O(n)$ in the worst case,
where $n$ is the total number of keys in the hash map.
The Logarithm Function
Some examples of this type of algorithms are:
-
Binary search: binary search involves searching for an element in
a sorted array. This algorithm is $O(\log n)$ because it utilizes
the divide and conquer technique, where the size of the array
reduces by half every iteration.
-
Calculate the 64-bit (or less) $n$-th Fibonacci number with
fast doubling method.
-
Balanced Binary Search Trees (e.g., AVL Tree, Red-Black Tree):
Searching, insertion, and deletion in balanced binary search trees
like AVL trees, Red-Black trees, or B-trees operate in $O(\log n)$
because the height of a balanced tree is $O(\log n)$.
-
Binary Heap Operations: Operations like insertion and extracting
the minimum (or maximum) in a binary heap take $O(\log n)$ time
because of heapify operations.
-
Exponentiation by Squaring: This algorithm utilizes the divide and
conquer method by checking whether $n$ is even or odd.
Input: a real number x; an integer n
Output: x^n
exp_by_squaring(x, n)
if n < 0 then
return exp_by_squaring(1 / x, -n);
else if n = 0 then
return 1;
else if n is even then
return exp_by_squaring(x * x, n / 2);
else if n is odd then
return x * exp_by_squaring(x * x, (n - 1) / 2);
end function -
Finding the Greatest Common Divisor (GCD)
The Linear Function
-
Finding the maximum/minimum of an array: We can only find the
maximum or the minimum of an array by going over all elements of
the array.
-
Linear search: If the elements are not sorted, then to find an
element in an array, we must perform linear search, which has the
worst-case complexity of $O(n)$. Similarly, traversing a linked
list is also $O(n)$.
-
Deletion and Insertion at random position in a linked list or
array. This tasks requires us to traverse over each individual
elements/nodes, which has the worst-case complexity of $O(n)$.
-
Comparing arrays, linked list, strings.
The $n \log n$ Function
These types of algorithms are usually optimized versions of $O(n^2)$
algorithms. Some examples of this type of algorithms are:
-
Fast Fourier Transform: FFT works by breaking down the computation
of the Discrete Fourier Transform (DFT), which is $O(n^2)$ into
smaller subproblems. For an input signal of size $n$, the FFT
algorithm splits it into two halves: one for the even-indexed
terms and one for the odd-indexed terms. It then recursively
computes the DFT of these smaller subproblems: the even and odd
indexed terms of the DFT.
-
Merge Sort, Quick Sort (on average), Heap Sort, AVL Tree Sort are
all $O(n\;\log n)$ algorithms.
The Quadratic Function
Quadratic time $\Theta(n^2)$ typically arises from a constant number
of nested loops over the input. Examples include selection sort,
bubble sort, and insertion sort (worst case), naive substring
search, and computing all pairwise distances in an array.
-
Two nested loops over $n$ elements:
$\sum_{i=1}^{n}
\sum_{j=1}^{n} 1 \in \Theta(n^2)$.
-
Insertion sort: $\Theta(n^2)$ in the worst/average case,
$\Theta(n)$ in the best (already sorted).
The Cubic Function
Cubic time $\Theta(n^3)$ appears in triple-nested loops and
classical algorithms such as naive matrix multiplication. Faster
asymptotic algorithms exist (e.g., Strassen's $\Theta(n^{\log_2
7})$), but with large constants and practical trade-offs.
The Exponential Function
Algorithms of this type are generally very bad. Some examples are:
The Factorial Function
-
The Traveling Salesman Problem (TSP) - Brute Force Approach: Given
a set of cities, find the shortest possible route that visits each
city exactly once and returns to the origin city. A brute force
approach checks all possible permutations of the cities to find
the optimal solution.
-
Generating Factorials: Given a set of integers $S=\{1, 2,
\ldots, n\}$. Since there are up to $n!$ permutations of
elements of this set, generating all possible permutations will
require $O(n!)$.
Other Irregular Functions
- Square-root time: $\Theta(\sqrt{n})$ or $\Theta(n\sqrt{n})$
appears in number-theoretic sieves and some block-decomposition tricks.
- Polylogarithmic: $\Theta(\log^k n)$ for fixed $k$ occurs in balanced
trees and multi-level indexing.
- Iterated log: $\log\log n$ and $\log^{(*)} n$ arise
in specialized data structures.
- Inverse Ackermann: $\alpha(n)$ (essentially a constant in practice) appears in union-find with path compression and union by rank;
overall operations can be $\Theta(m\,\alpha(n))$ for $m$
operations on $n$ elements.